Sigmax Stack in 5G Applications
5G Direct Ingest
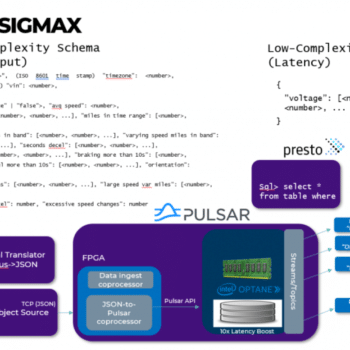
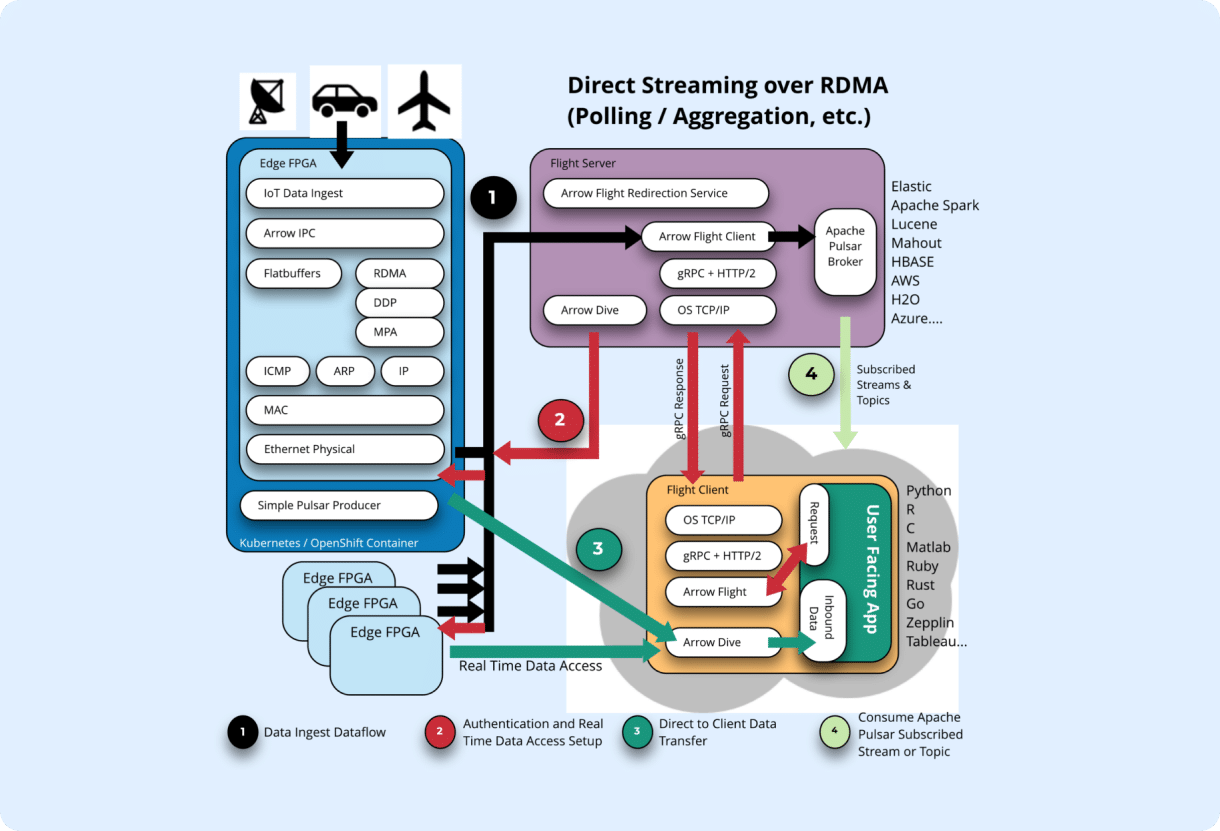
The dataflow pictured above features elements of the SigmaX stack and also demonstrates some roadmap items of the SigmaX stack to show the potential for setting up a direct data connection from FPGA-point-of-ingest connectivity directly to interested (and authenticated) client consumers. What follows is a walk-through of the dataflow and explains the ingest phase (black), setup and authentication phase (red) and finally dataflow (green).
Pictured above, the client exists in a cloud location – however this does not necessarily have to be the case! Clients in this architecture are locality independent. Clients can be streamed real-time data and historic data if they are co-located on the edge device, within the flight server (fog), enterprise or cloud. Of exceptional interest to 5G dataflow requirements is the extremely low latency delivery of data from the 5G wireless network to active clients. The above data architecture enables the back-end compute infrastructure to keep up with and deliver upon the exceptional performance characteristics of the 5G wireless front-end.
The major elements of this architecture all exist in open source formats. This feature brings huge benefits by way of guaranteed availability, clear and transparent source code, and ongoing feature development by the open source community.
We begin with a dataflow as viewed from a User Facing Application sitting in the bottom right corner. The beauty of this architecture is that it gives a relatively high level application, written in any one of a number of convenient languages, access to not only low latency streaming analytic data (via Apache Pulsar) but also immediate access to discover and directly stream real-time data at the very point of ingest to the client application.
How this is achieved begins in the upper left-hand corner of Figure 1 where data is ingested on an edge device via a hardware accelerated port containing a smart-NIC based on Intel off-the-shelf FPGA technology. This can be a shoebox-sized server or small cluster of servers ingesting FOG data from many sensors simultaneously and without centralized coordination. They are simple data “Producers”. As an aside, currently owned commodity hardware can be modified with the addition of a small low profile NIC card to enable real-time direct to client data ingest or compatible systems can be procured from SigmaX.ai.
The ingested data is first coerced into Apache Arrow columnar-optimized data format at the edge and handed off to Apache Arrow Flight while still on the NIC. Arrow is an important standard to follow because it is both a zero-copy format, but also eliminates the artificial need to convert data between at-rest storage format (strings) and in-process computable format (bytes.) Following the black arrows in Figure 1, ingested data is aggregated at Flight Severs which run a full Apache Pulsar Broker. This data architecture views Apache Pulsar as a preferred analytics message broker because it addresses several pain points for IoT-like systems.
Pulsar:
- Is an exceptionally low latency Message Broker with built-in Geo-Replication
- Supports subscribable streams and topics (millions of combined streams/topics.)
- Can run even lower latency AND order of magnitude increase in performance with the addition of Intel OPTANE memory to server systems (Swapping out DDR4)
- Is interesting for ultra-low latency 5G network carriers for example to ingest IoT Data
- Supports Tiered and Cloud-Enabled Storage for archival (S3 etc.)
- Supports Data Replay from Offset, which provides for: disaster remediation and built-in data integrity checks.
- Supports Query across many levels of Tiered Storage with varying performance profiles relative to latency and throughput concerns.
In this data flow our client app has access to two forms of streaming analytic data – data produced by Pulsar on subscribed streams (to include historic data) AND real-time data at the point of ingest via Apache Arrow Flight and Arrow Dive (which is a roadmap item, to be developed initially by SigmaX.ai and made available as Open Source Apache 2.0 license.)
The red arrows in Figure 1 illustrate Arrow Dive functionality. In this case the client requests data via a gRPC request placed to Arrow Flight servers. The client is securely authenticated, and data discovery takes place. Arrow dive enables direct data transfers for a limited time to authenticated clients. A gRPC response is sent to the client containing a stub which acts as a ticket or permission to listen to the FPGAs. Green arrows in step #3 show an authenticated client listening to real-time data being ingested via multiple smart NICs. This data is transferred directly via RDMA from Ingesting Smart NICs to our client API’s.
Apache Arrow + Pulsar 5G Dataflow
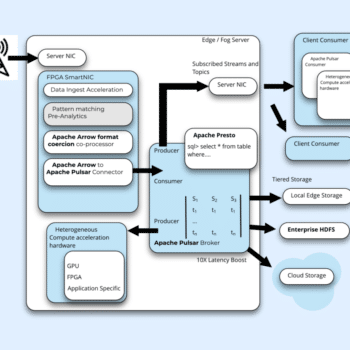
An Open Source, Low Latency 5G Ingest is pictured above. This time we look at ingesting data without the roadmap items such as Arrow Dive. In this architecture the nature of Pulsar as the open source community’s lowest latency messaging solution is central, as is hardware assisted record format coercion being performed in this case by what amounts to an Apache Arrow co-processor.
5G Wireless network data connects via a cluster of fog servers sitting near to edge devices. Data is ingested via the host NIC interface and then offloaded to an FPGA enabled Smart-NIC. At this point in the dataflow customers have an option to insert an additional “pattern matching or pre-analytics” phase where the parallel executional nature of the FPGA will allow for real-time custom data transformation or feature extraction to take place. This is step is optionally developed by the customer (Curated Appliances from SigmaX can ship configured with full Intel tools and containerized environments in support of this development) or Work can be scoped directly with SigmaX (based on engineering availability*).
The data is then coerced to Apache Arrow in the FPGA hardware and consumed by Apache Pulsar running on the host. Pulsar brings its usual list of benefits (Data Geo-Replication, Scale-out across many ingest servers etc.) and we add Intel OPTANE memory to further reduce Apache Pulsar Send() latency by an order of magnitude. Data is placed in streams and topics based on schema and unknown schemas are recognized as such and placed in their own streams. Pulsar’s durable storage for aging data includes local storage at the edge, in the enterprise and in the cloud. We connect pulsar to an array of supported heterogeneous hardware accelerators either on the Fog cluster or as client consumers on the network.